Removing tags from HTML prior to parsing
December 4, 2016
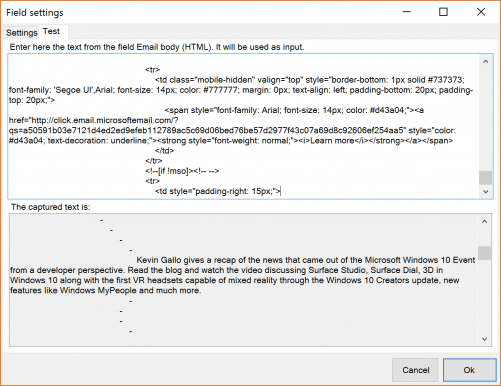
Ideally, the emails needed to be parsed come in plain text or using a very simple HTML formatting. This helps setting up Email Parser a lot but the most common scenario is that the emails you need to be parsed have many HTML tags, complex formatting, fancy fonts etc. This makes text capturing like digging for data. A very useful way to prepare the HTML body of an email to be parsed is to remove all the HTML tags first. We can do this creating the following field (called test here) in an email parser item:
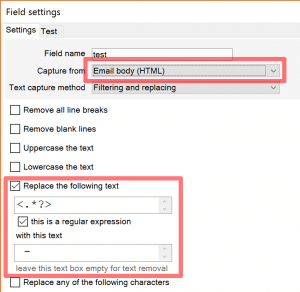
<.*?>
Which basically means:
Take anything that starts with '<' and ends with a '>'
And we replaced here the matching text with a ‘-‘. You can put here anything, even nothing at all if you want the HTML tags to be removed. We used ‘-‘ to show you that the HTML tags have been actually removed.
Well, time for testing. Let’s take one of those fancy emails full of formatting: