Multiple step parsing
See also:
What is a field?
What is an email parser?
When you need to extract a specific piece of text from an email, you do not have to write a single rule that captures it directly from the full email body. Instead, you can break the task down into multiple steps. Each step is represented by a parsing field, and each field takes the output of the previous one as its input. This makes the parsing process much simpler and more reliable.
This is a very common technique. Whenever a parsing task starts to get complicated, the best approach is to split it into two or more separate steps until you get exactly the result you need.
Example: extracting a street address
Imagine you receive emails that contain a full address somewhere in the body. You need to extract just the street name from that address. Instead of trying to capture the street directly from the entire email, you can do it in two steps:
- First step: identify and capture the text block that contains the full address from the email body.
- Second step: from that address block, extract only the street name.
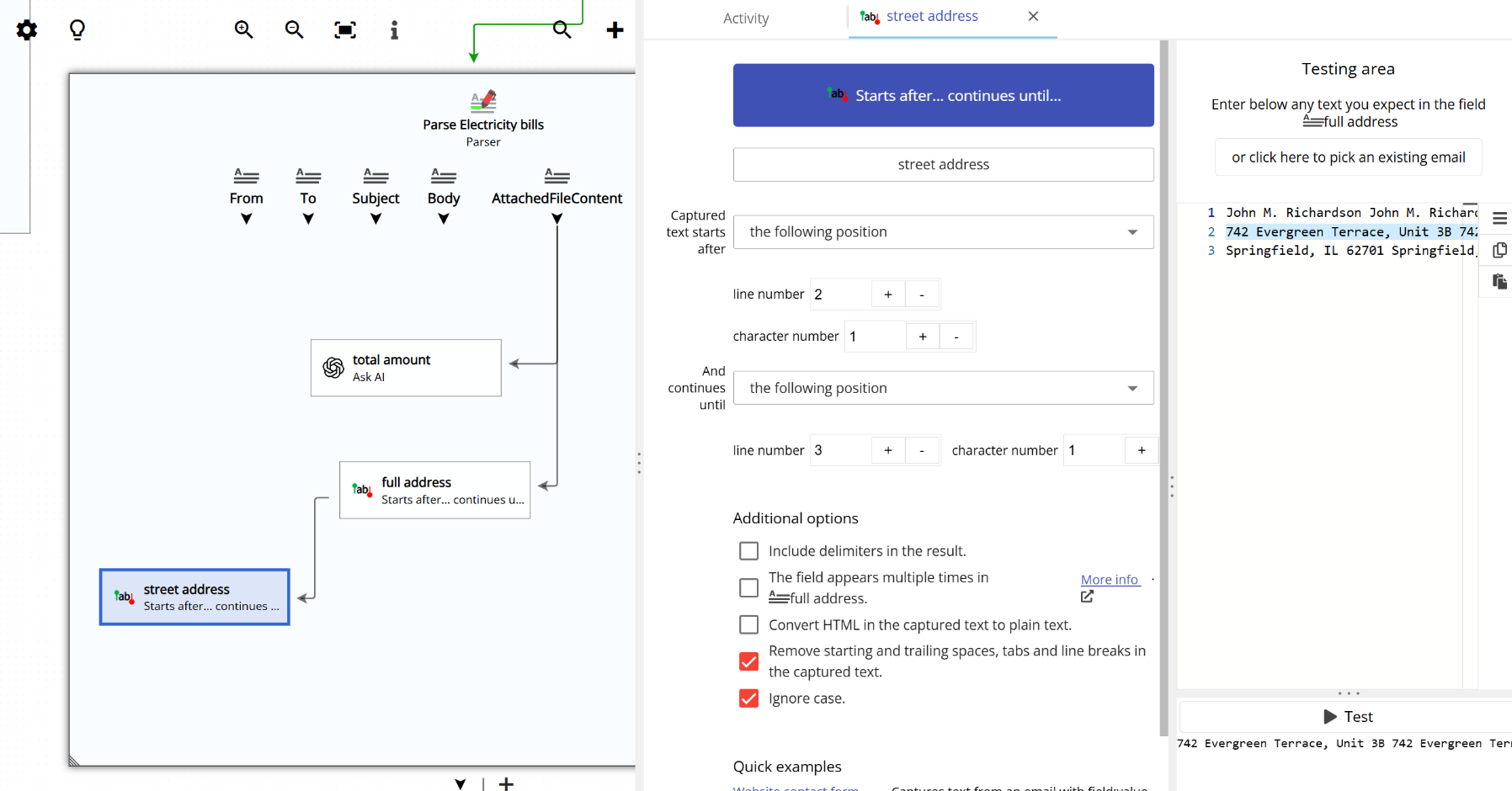
The following screenshot shows how this two-step parsing is configured. The first field captures the full address from the email, and the second field takes the output of the first one and extracts just the street:
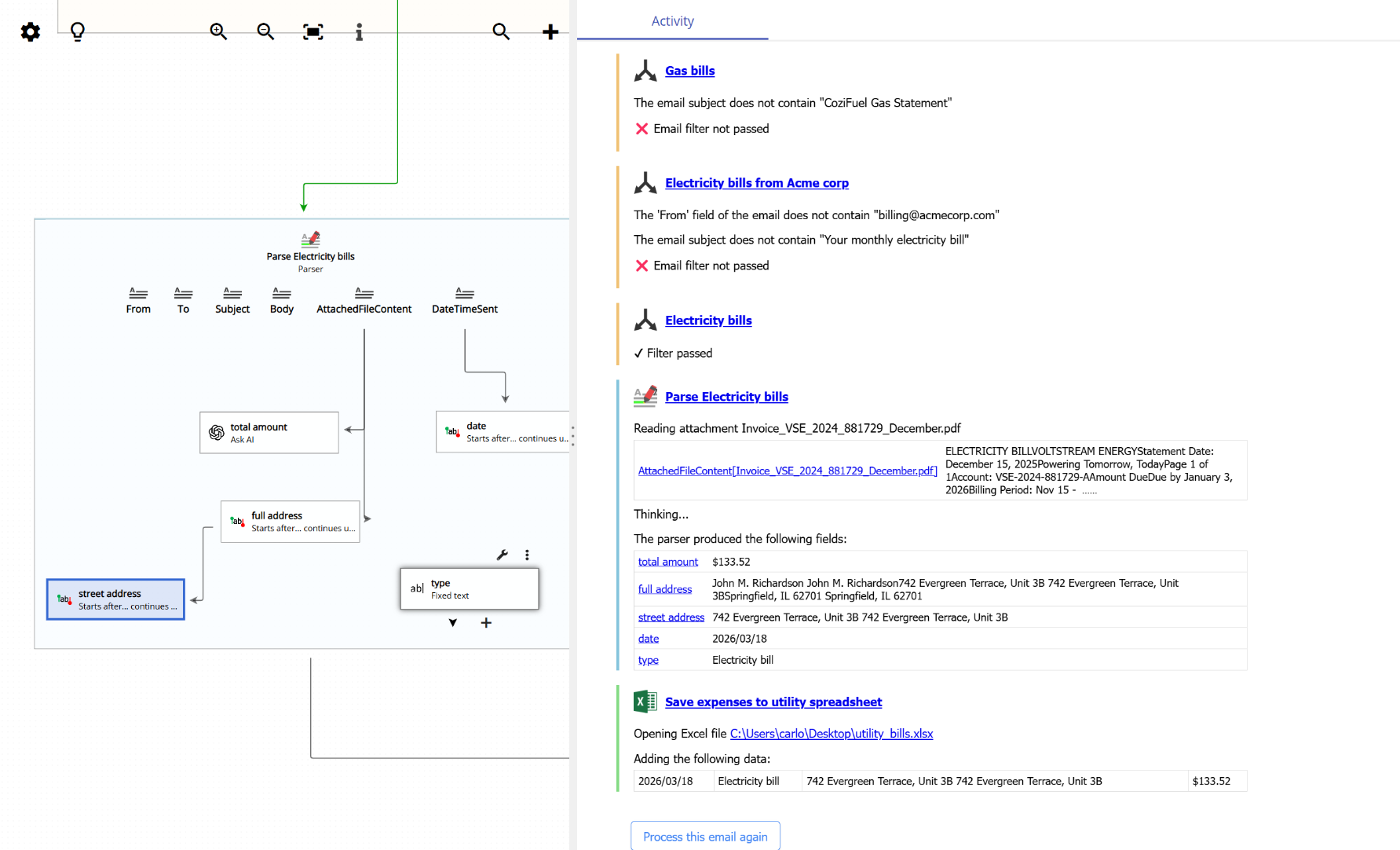
And here you can see the result of running both steps. The first field gets the full address block, and the second field narrows it down to just the street:
Example: using AI as a second parsing step
Multiple step parsing also works very well with AI-powered fields. For instance, if you need to extract a specific value (such as the total amount in EUR) from an email, you can first capture the relevant text block using a regular parsing field, and then use an LLM (an AI agent) as the second step to extract the value from that block.
This approach has an important benefit: the AI only receives the text block as its input (its context, in AI terms), rather than the full email. Because the AI is working with a smaller and more focused piece of text, its output is more accurate and predictable.
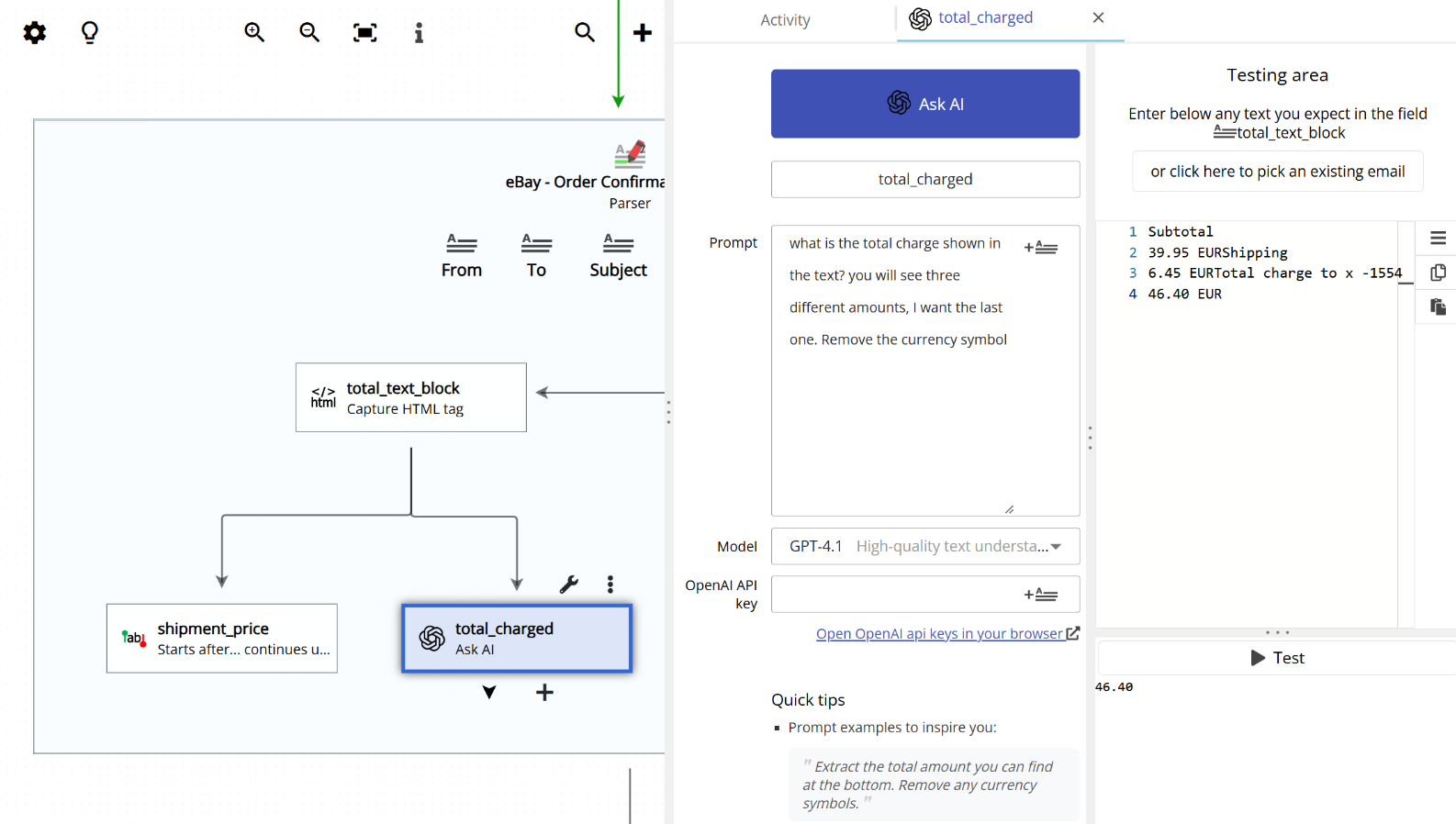
In the screenshot above, the first field captures a block of text from the email body. Then, the AI field takes that block as input and extracts the total EUR amount. Since the AI is not exposed to the entire email, it focuses only on the relevant text, which leads to better and more consistent results.