Capturing an HTML tag with XPath
See also:
Overview on the different methods of how to capture an HTML tag
XPath expressions are used to locate a specific HTML tag in an HTML document. You can use them to capture a subset of text from the HTML version of the email body.
The XPath concept is very similar to the path expressions used to identify folders in a computer (C:\Users\John\My documents…) but HTML tag names are used instead of folder names. For example, given this HTML document:
<table> <tbody> <tr> <td>Name:</td> <td>John Doe</td> </tr> <tr> <td>Phone:</td> <td>1234567890</td> </tr> </tbody> </table>
That looks like this (it is just a table):

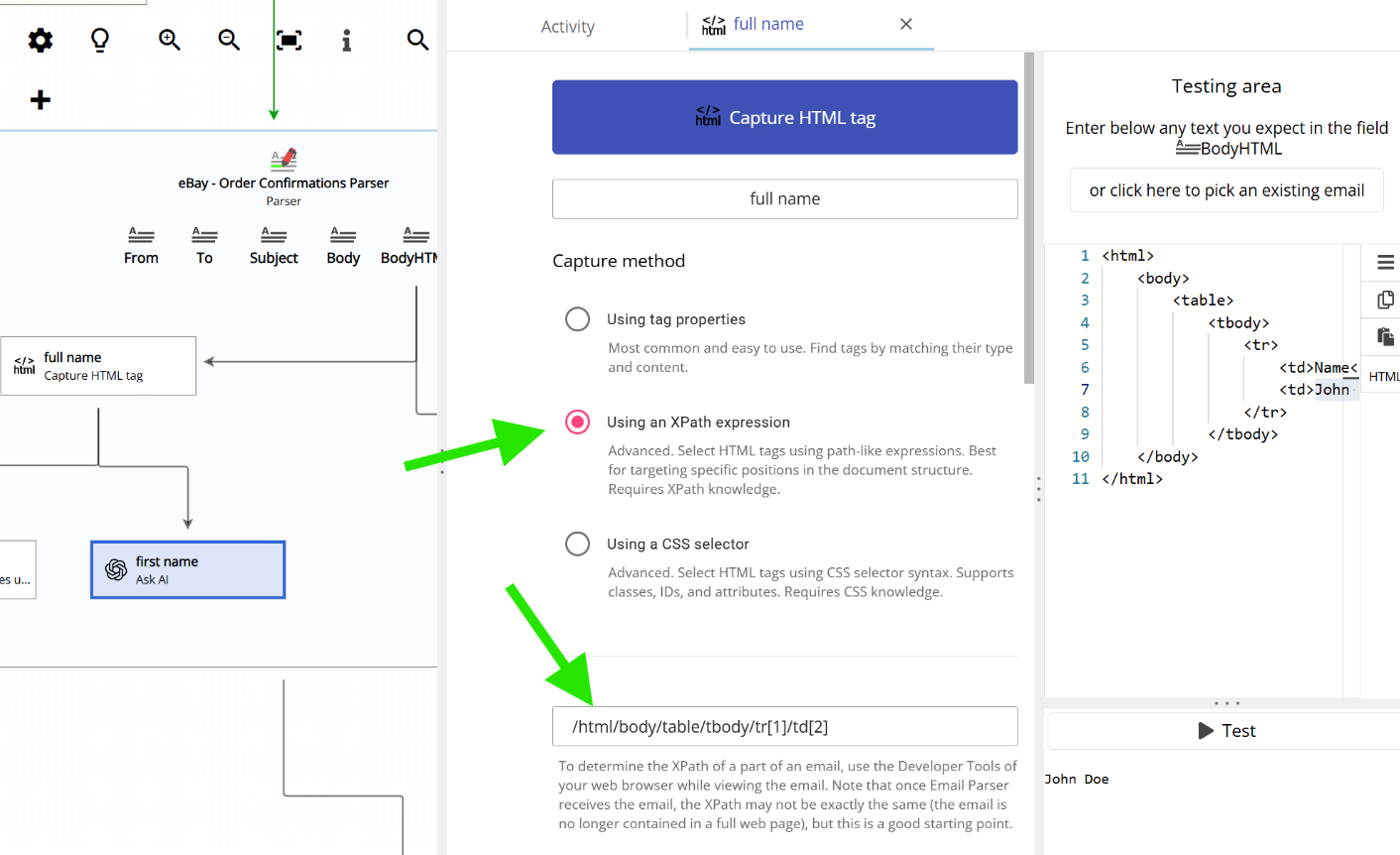
If we use the following XPath expression:
/html/body/table/tbody/tr[1]/td[1]
The captured text will be “Name”.
If we use this one instead:
/html/body/table/tbody/tr[1]/td[2]
The captured text will be “John Doe”.
This XPath expression, in a more natural language, would be something like this:
“Take the <html> tag, then find the <body> tag inside it, then within the <body> find <table> and then find <tbody>. Inside <tbody> take the first <tr> tag and then inside it take the second <td> tag.”
Capturing text in complex HTML code
The HTML code of an email is usually more complicated (or large) and has many levels of tags. This makes it extremely difficult to find the correct path to the text you want to capture. In these cases, it is better to rely on the CSS properties of the tag. For example:
(... a very long list of HTML tags) <tr> <td style="font-size:14px;font-weight:bold">John Doe, May the 3rd 1995</td> </tr> (... and even more incomprehensible HTML ahead)
The XPath expression to capture “John Doe, May the 3rd 1995” without using CSS properties would be:
/html/body/table[3]/tbody/tr/td[4]/table/tbody/tr/td/div[4]/table/tr/td[5]/
As you can see, the expression above is too complicated and we probably have spent too much time finding it. Using the CSS properties can be much easier:
//td[@style="font-size:14px;font-weight:bold"]
Both XPath expressions produce the same output: “John Doe, May the 3rd 1995”.
Note the “//” at the beginning. It means that we want to capture a <td> tag located anywhere in the HTML tag tree, regardless of its parent tags. Also, the value between the brackets allows us to specify that we only want the <td> tags that have this specific styling. You can also use the [@property=value] syntax for any other HTML tag properties such as class, id, name, etc.
How to work with XPaths in Email Parser
Writing an XPath expression for capturing text from an email in Email Parser usually involves these steps:
- Click on “Add field” in the workflow diagram.
- Choose “Capture HTML tag” as the capture method.
- Choose “Use XPath”.
- Locate an email that you want to use for testing. You can do this by opening your email account and clicking an email on the list.
- Go to the “Fields” tab (in the email account email listing) and click on the field BodyHTML.
- Copy all the BodyHTML content to the testing area of the field we created in step 1.
- If the HTML code is badly formatted, difficult to follow, or has no tabs, use an HTML formatter like https://htmlformatter.com. The parsing results do not change if you “tidy” the HTML code. It just makes it easier to read.
- Type any XPath on the left. You will see that, as you type, Email Parser will evaluate it and show the results in the testing area. Start with something easy, like a title or something you can easily locate in the HTML code. Then try to add more complexity to the XPath to get what you want. You will see that this will require a lot of trial and error.
- Once you see that the XPath expression you have written works for that testing BodyHTML, go and get the BodyHTML of another email. Check that the results are as expected with other emails.
The very basics of the XPath syntax: quick reference
| XPath expression | Meaning |
|---|---|
| /tagname | Captures the <tagname> element at the root of the document (a root tag is a tag not contained in other tags). |
| //tagname | Captures any <tagname> regardless of where it is located in the tag tree. If you enable “Capture more than one HTML tag” in the additional options, more than one value can be captured. |
| //tagname1/tagname2 | Captures the <tagname2> elements contained in a <tagname1>. <tagname1> can be anywhere in the document. |
| //tagname1/tagname2[2] | Captures the second <tagname2> element contained in a <tagname1>. <tagname1> can be anywhere in the document. |
| //tagname1//tagname2 | Captures the <tagname2> elements contained in a <tagname1>. <tagname1> can be anywhere in the document and <tagname2> must be contained in <tagname1>, but it is not required that <tagname2> is the direct child of <tagname1>. |
| //tagname1/*/tagname2 | Captures all <tagname2> elements that are grandchildren of <tagname1> elements. |
| //tagname[@property=value] | Captures any <tagname> with a property having that value. For instance, //div[@class=”green-header”]. |