July 19, 2023
In the realm of data management and analysis, finding efficient and accessible solutions is paramount. One such solution is the utilization of CSV files which provides a straightforward and standardized format for storing and exchanging structured data. From data scientists to business analysts, professionals from various domains benefit from the simplicity and versatility of CSV files.
Exporting emails to CSV (Comma-Separated Values) format can be a valuable way to convert and organize your email data. Email Parser is a versatile tool that enables you to extract data from emails and export it to CSV effortlessly.
read more …
July 18, 2023
In today’s digital age, emails play a crucial role in communication and information exchange. Often, important data is buried within email messages, making it essential to extract and organize that information efficiently.
This article explores the process of extracting data from emails and sending it to Excel, providing valuable insights on why it is beneficial and how to achieve it seamlessly.
read more …
July 14, 2023
Nowadays, email and email management is the cornerstone of most businesses and marketing campaigns. The information gateway is the e-mail, but the key point is not to obtain this information, but to be able to optimize its management.
The automated and optimized process of sending this data to a CRM, a spreadsheet or any database is what makes the difference as the next step of the workflow.
Email Parser is a powerful tool that simplifies this process by allowing you to extract data from emails and export them directly to Google Sheets.
The way in which implementing this data management tool will revolutionize your business is a reality that we want to share with you in this article. Our software allows you to export emails directly to Google Sheets, streamlining your data management process.
With this functionality, you can seamlessly transfer email data to Google Sheets, eliminating the need for manual entry and ensuring accurate and up-to-date information.
read more …
November 10, 2022
Microsoft has stopped accepting plain old authentication on Office 365 and if you are using their cloud to host your email you may have seen how your email sources suddenly stopped working. More information about the Microsoft change
here.
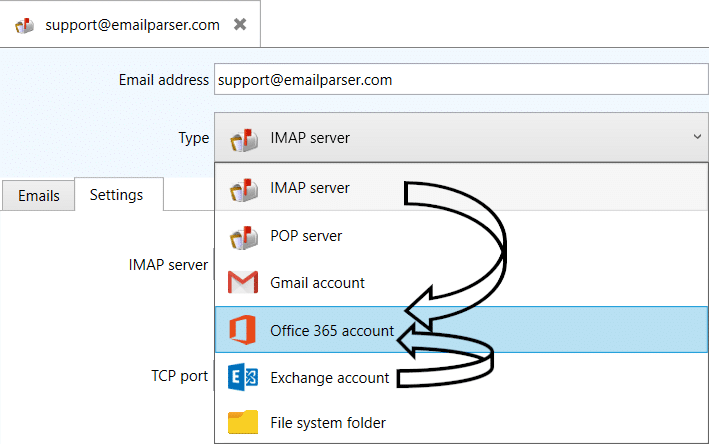
To fix this issue you need to update Email Parser to the latest version and use the “new” Office 365 protocol as seen below:
If you don’t see the option in Email Parser (and you are using the Windows app) please update to the latest version. Just downloading and installing the trial version will update your files and keep your settings.
And if you experience any issue or have any problem feel free to
ask us.
September 29, 2022
Starting as of today, we are increasing the Windows app price from USD 79 plus taxes to USD 145 all taxes included. This price change applies only to the Windows app and for the new customers. Existing customers are not affected.
I have a running subscription. Will I pay more in the next charge?
No. Price increase is only applied to new customers. We keep the price for the existing customers. We want to thank the loyalty of them as many purchased a license key more than 5 years ago and happily moved with us to the new subscription model implemented last year.
From USD 79 plus taxes to USD 145 all taxes included. Why so complicated?
Previous pricing was a mess. Some users paid only USD 79 if they were tax exempt, others paid more depending on their location. We simplified it with a fixed price for everyone, as most software providers do.
Is the Web app affected by this price change?
No, the web app keeps the same price and we do not plan to change it anytime soon.
Why do you increase the price?
Hosting and other supplier costs have risen a lot during the last year. Also, we recently put a lot of development resources on new versions and plan to keep the effort in the future.
I find the new price of the Windows app expensive
Sorry for that. If you are a non-profit, a charity or an educational institution, we offer big discounts. Please, send us an email to support@emailparser.com
May 24, 2022
This is mainly a bug fixing release where the most notable fixes are related to errors and missed emails when processing large batches of emails on some email accounts. Other minor improvements have also been made, such as the use of plain text logs (instead of HTML) and cosmetic improvements in the user interface. The detailed list of changes is as follows:
- Fixed the issues that caused unprocessed or missed emails under some configurations.
- Fixed random process restarts when processing large batches of emails (>1000).
- Lower memory footprint when processing large batches of emails (>1000).
- Field testing now highlights delimiters in starts after… continues until…, not only the captured text. When using capture groups in regular expressions the capture group is also highlighted in the input text. This makes easier coming up with the correct parsing rule.
- When an email account connection is failing, reconnecting now happens faster.
- HTML is no longer used as a format for the log. Plain text (TXT) is now used for better integration with log tools and text editors. It also makes searching for errors quicker in large logs.
- Fixed bad filter combination execution when the rule “any of the following filters must block this email as well” was selected. Now it always works as expected.
- Internal database size is now allowed to grow bigger. If you process thousands of emails and see the message “This email has been processed but its log has been removed to save space database space.” Now this message will appear less often.
- Fixed the error “Object reference not set to an instance of an object” when reading attached files in the testing area of the field settings.
- Simplified Attachment reader. Now relevant options are shown up. Better ‘Quick tip’ explanations.
February 9, 2022
A new version of the Web App is now available. This update brings to the Web app the latest fixes that were done in the Windows App a couple of months ago. Also, we have applied other minor fixes and changes specific to the web version of Email Parser:
- Fixed some glitches that when working with Office 365 and IMAP servers. Mostly random server disconnections, missed or duplicate email processing and errors on when listing the list of emails.
- Totally rewritten sign-in and sign-up process. Simpler and cleaner look.
- Smaller web app size. Faster loading times.
- Many minor UI enhancements and fixes.
December 3, 2021
This new release comes with these changes:
- Better support for some newer IMAP servers. If you see the email list failing, updating will fix the issue.
- Improved user feedback when listing emails. A progress message is shown below the email list. Error messages are improved as well.
- Fixed connecting to Office 365 accounts with a big number of messages in a folder (+10K emails).
- New action available to apply a label to parsed emails. This way, you can track what happened with processed emails at a glance. Note that this is not related to Gmail labels.
- Minor improvements in the left panel arrows. Moving arrows with the mouse now is even easier.
November 2, 2021
This is mainly a bug fixing release where some minor issues in the user interface have been addressed. It also contains fixes for the connection problems with Office 365 that some users noticed.
The detailed list of changes is as follows:
- Fixed connection stability issues when connecting to Office 365 through Exchange.
- Fixed connection stability issues when connecting to Office 365 through its own protocol.
- Fixed the UTF-8 encoding error that appeared when connecting to Office 365 servers via IMAP.
- Fixed the duplicate processing of some Office 365 emails when deleting or moving emails.
- Fixed the Internet Explorer Trusted Zones warning after installing Email Parser in Windows Server.
- Moving the arrows in the left panel is now easier thanks to an increased draggable area.
- TLS is now set as default in the send email and forward email actions.
- Fixed the OAuth panel not updating when the email address changed (OAuth is used in Office 365, Gmail and Google Sheets).
- Fixed the “Item with id X does not require OAuth to work” error of the OAuth panel.
- Updated the “quick tip” image of the conditional run action.
- Fixed the word wrapping that was incorrectly applied on the output of the testing area when editing the field parsing rules.
- When a field is of type Attachment reader now an arrow is drawn starting from the field AttachedFileName in the left panel.
- Added a link to the Microsoft connectivity test under the Exchange source quick tips.
- Removed the menu icon that was incorrectly showing in the processed email log.
- Better placement of toolbar icons on narrow screens.
- Updated icon for the script action (C#).