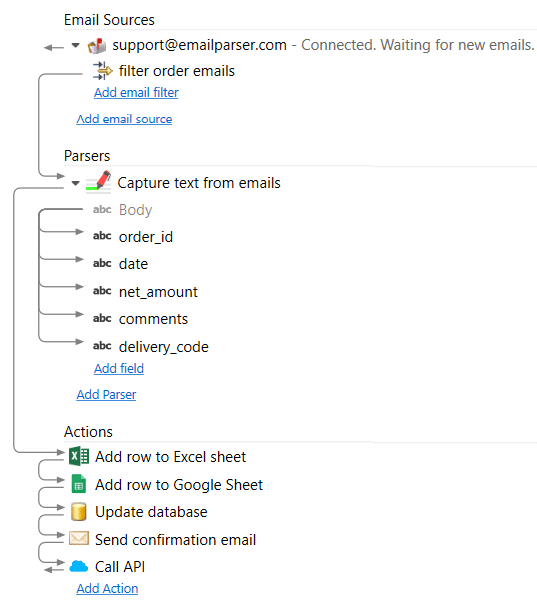
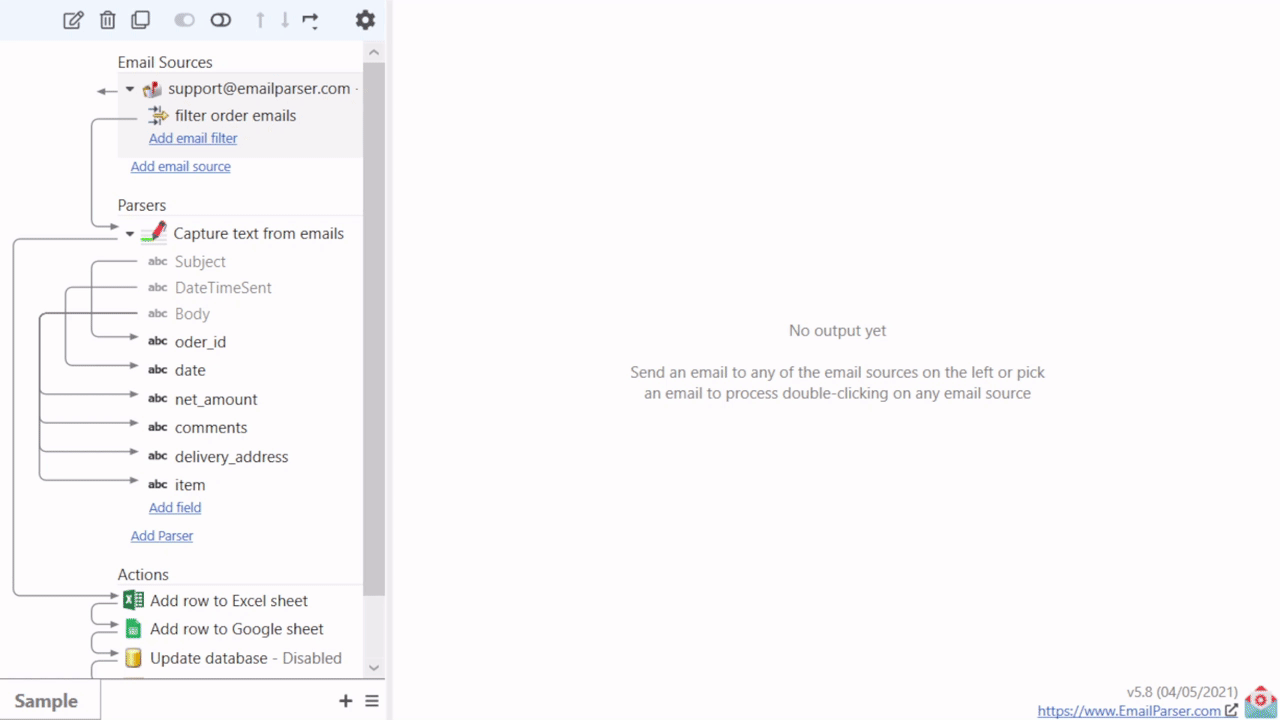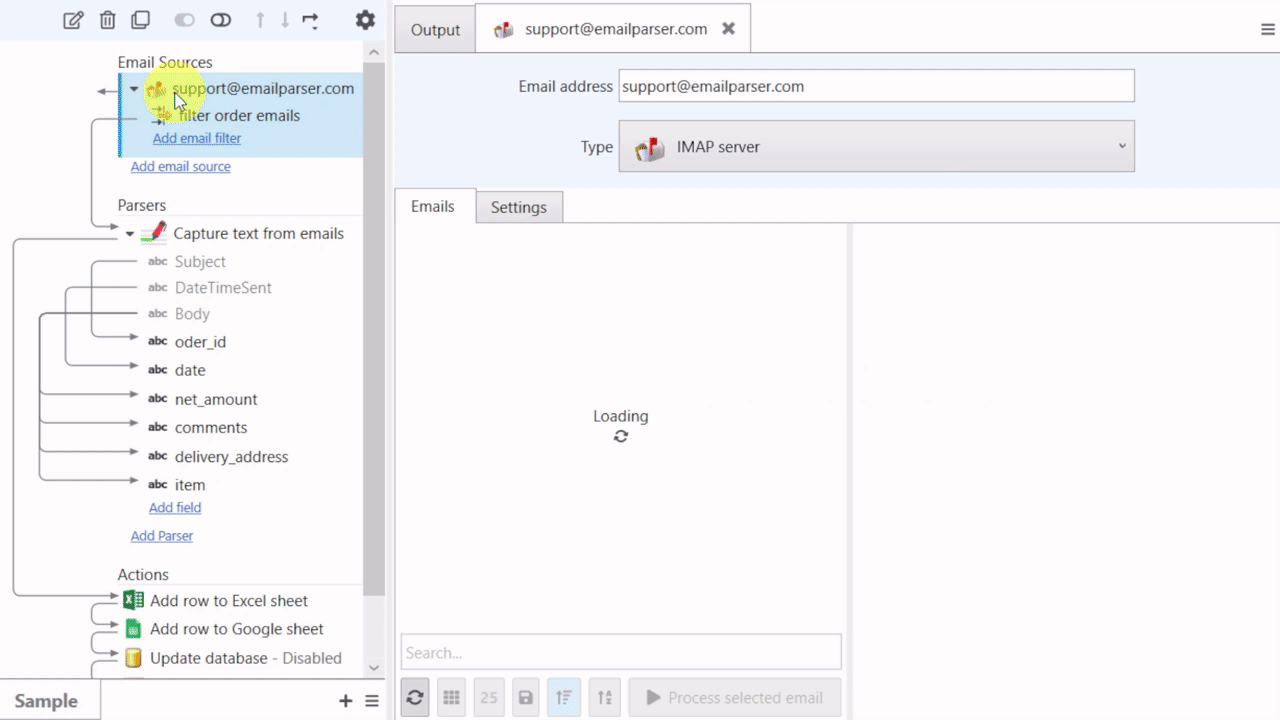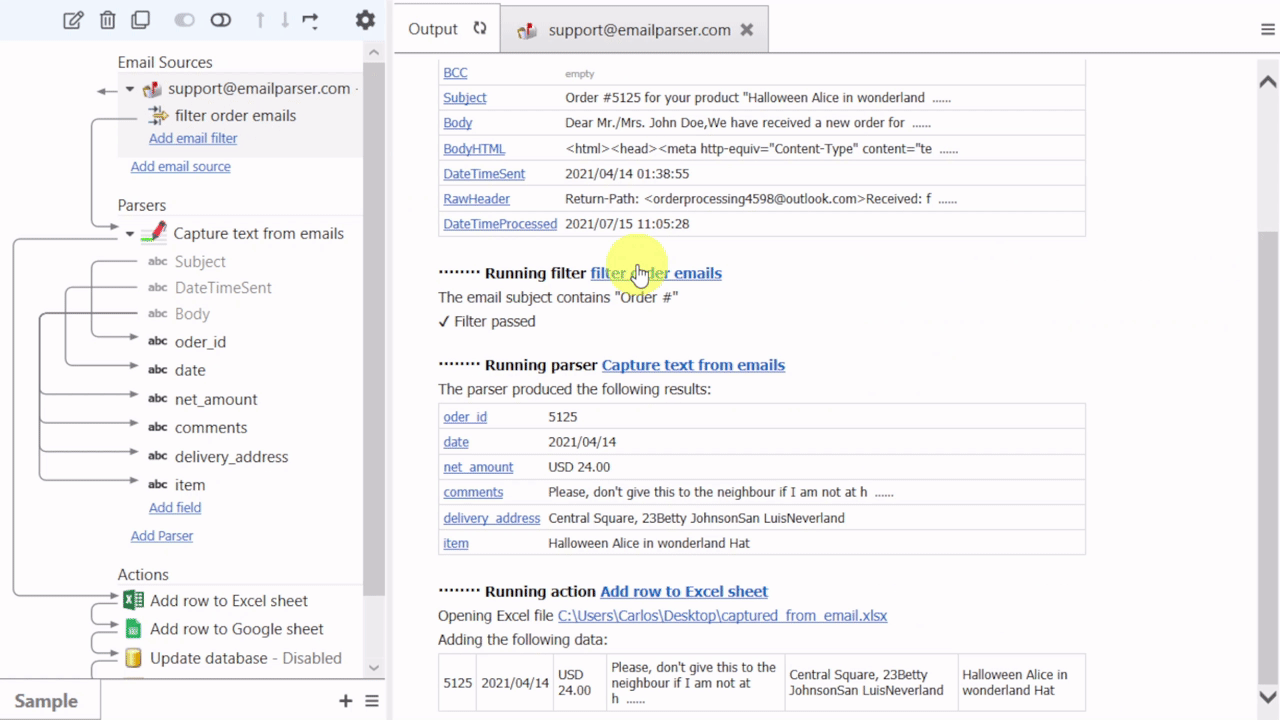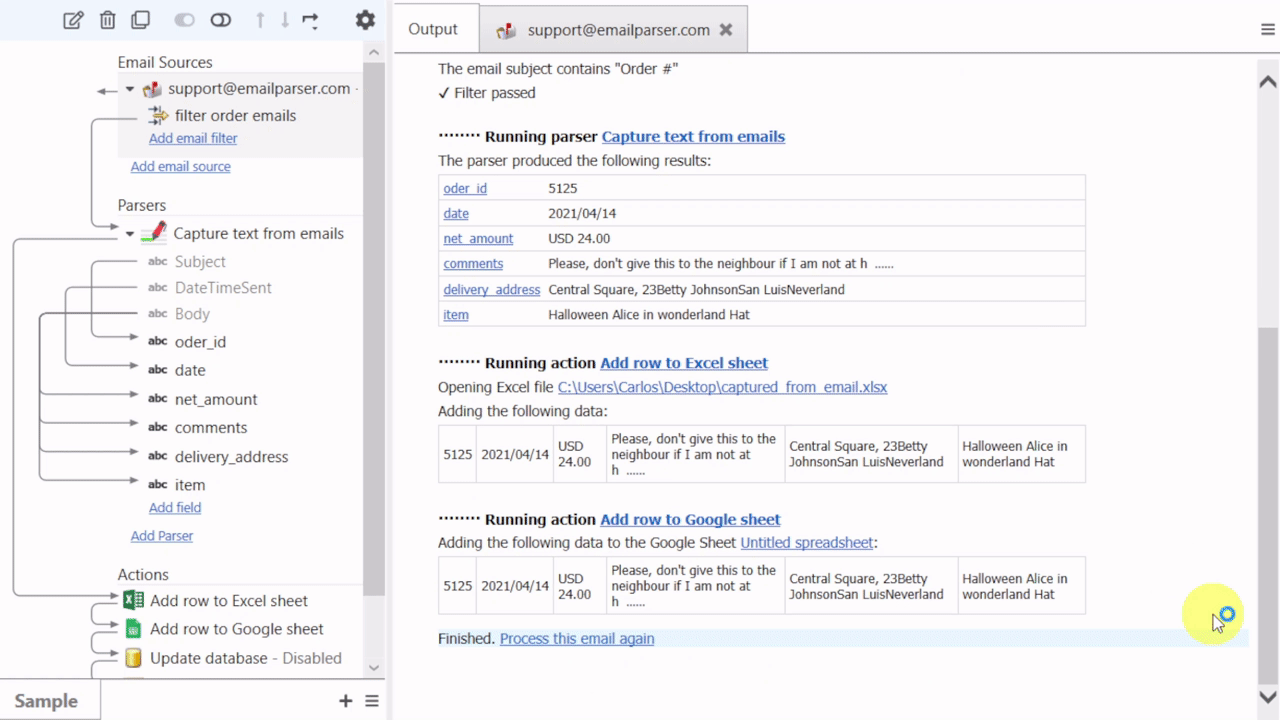
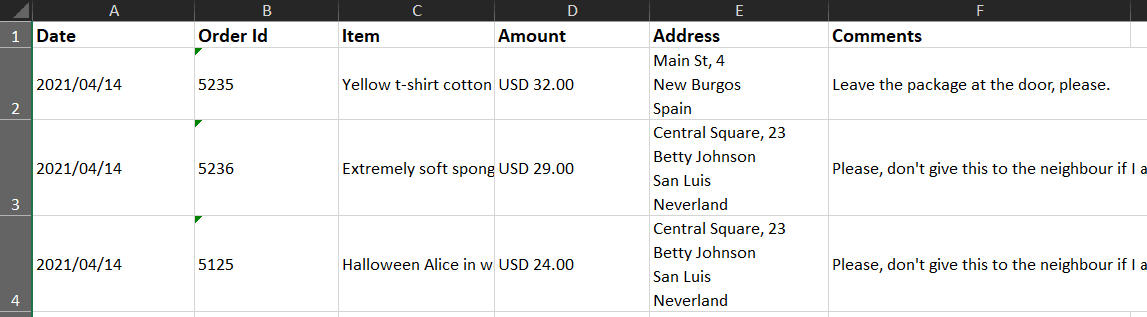
Email Parser is a tool to capture text from incoming emails. It fills the gap between the emails you receive and a database, a spreadsheet or any other program that need to be fed with the email contents. The steps involved in the email processing are shown in the left panel of Email Parser:


 Go to the Web app
Go to the Web app